L'architecture hexagonale
Ou comment créer votre application de telle manière pour qu’elle puisse fonctionner sans interface utilisateur ou sans base de données vous donnant ainsi la possibilité d’y exécuter des tests de régression, pour qu’elle puisse fonctionner même en cas d’indisponibilité de la base de données, et enfin pouvoir l’interconnecter avec d’autres applications sans que l’utilisateur ait à faire quoi que ce soit
Avant-propos du traducteur : certains mots ou certaines expressions ont été laissées en anglais dans la présente traduction de part un usage plus répandu dans le langage courant. Toutefois pour satisfaire tous les lectorats possibles, des traductions françaises de ces mêmes mots ou expressions sont présentes en notes de bas de page.
Ce texte est aussi disponible :
- en japonais http://blog.tai2.net/hexagonal_architexture.html
- en espagnol http://academyfor.us/posts/arquitectura-hexagonal par Arthur Mauricio Delgadillo
L’article d’origine mis à jour est disponible à cette adresse http://wiki.c2.com/?HexagonalArchitecture et là http://wiki.c2.com/?PortsAndAdaptersArchitecture
Vous pouvez aussi consulter la FAQ sur l’architecture hexagonale (EN) (discussion: Re: Hexagonal Architecture FAQ)

Le modèle : Ports & Adapters1 (« Structure de l’objet »)
Nom alternatif : « Ports & Adapters »
Nom alternatif : « Architecture hexagonale »
But recherché
Permettre à une application de pouvoir :
- être pilotée indifféremment par des utilisateurs, des programmes, des tests automatisés ou par des traitements batchs,
- être développée et testée de manière isolée de tout dispositif éventuel pouvant l’exécuter et de toute base de données.
Lorsqu’un pilote, quel qu’il soit, veut utiliser l’application sur un port donné, il envoie une requête qui sera convertit grâce à un adaptateur spécifique à la technologie utilisée par le pilote, en procédure d’appel ou en message utilisable, qui à son tour sera passé au port de l’application. Il est à noter que l’application est complètement ignare de la technologie du pilote.
Lorsque l’application a quelque chose à envoyer, elle le fait à travers le port vers l’adaptateur, qui à son tour créé le signal approprié attendu par la technologie réceptrice (humaine ou non). L’application a, sémantiquement parlant, des échanges avec les adaptateurs de tous côtés, sans vraiment connaître la nature des choses avec lesquelles elle communique de l’autre côté des adaptateurs.
Illustration 1 : L’architecture hexagonale

Motivation
L’un des plus grands écueils de ces dernières années dans le domaine informatique a été l’immixtion de la logique métier dans le code de l’interface utilisateur. Le problème engendré est de trois ordres :
- Tout d’abord, il est impossible de tester le système de manière exhaustive avec des logiciels de tests automatisés car la partie de la logique qui doit être testée est dépendante de la partie visuelle dont les éléments sont amenés à changer régulièrement, comme, par exemple, la taille d’un champ de saisie ou le placement d’un bouton ;
- Pour la même raison, il est impossible de remplacer une interaction humaine sur le système par des batchs ;
- Et toujours pour la même raison, il est difficile voire impossible de permettre au programme d’être piloté par un autre programme si cela s’avérait intéressant.
La solution tentée dans beaucoup d’entreprises est de créer une nouvelle couche au niveau de l’architecture, avec la promesse que cette fois-ci, si pour de vrai, qu’aucune logique métier ne viendra fourrer son nez dans la nouvelle couche. Toutefois, comme il n’existe aucun mécanisme permettant de détecter une violation de cette promesse, l’entreprise découvre quelques années plus tard que cette nouvelle couche se retrouve parsemée de logique métier et le vieux problème refait surface.
Imaginez maintenant que « chaque » morceau de fonctionnalité que l’application offre soit rendue disponible à travers une API (interface d’application programmable) ou un appel de fonction. Dans ce type de situation, le département Test ou Assurance Qualité est en mesure d’exécuter des scripts de tests automatisés pour détecter que rien de nouveau n’est venu casser une fonction qui fonctionnait auparavant. Les experts métiers peuvent créer des cas de test automatisés, avant que les détails de l’interface utilisateurs soient finalisés, ce qui permettra de dire aux développeurs qu’ils ont fait leur travail correctement (et ces tests deviennent ceux exécutés par le département Assurance Qualité). L’application peut être déployée en mode « headless »2, dans laquelle seule l’API est disponible. Dans ce cas de figure, seuls d’autres programmes peuvent utiliser les fonctionnalités de l’application — cela simplifie la conception générale des suites d’applications complexes, et cela permet aussi aux applications offrant des services B2B de faire appels à leurs fonctionnalités réciproques à travers la Toile sans interventions humaines. Enfin, cela permet aux tests de régression automatisés de détecter les violations faites à cette promesse de garder en dehors de la couche de présentation la logique métier. L’entreprise peut alors détecter, puis corriger cette infiltration.
Un autre problème analogue et tout aussi intéressant, existe dans ce que l’on désigne habituellement par le terme « l’autre côté » de l’application, autrement dit quand la logique applicative se retrouve assujettie à une base de données ou à un autre service externe. Lorsque le serveur de la base de données tombe, est en cours de maintenance ou est remplacé par un autre, les développeurs se retrouvent alors dans l’impossibilité de travailler en raison de cet assujettissement. Ce qui a pour conséquence d’engendrer des coûts liés au retard pris accompagnés souvent par des ressentiments entre certaines personnes.
Il n’est pas sûr que les deux problèmes évoqués de « chaque côté » soient liés, mais il y a une certaine symétrie entre les deux qui apparaît quant à la nature de la solution.
De la nature de la solution
En réalité, les problèmes du côté utilisateur et du côté serveur ont pour origine une même erreur de conception et de développement à savoir — l’enchevêtrement des logiques métier et des interactions avec des entités externes. L’asymétrie à exploiter n’est pas entre le côté « gauche » ou « droite » de l’application mais entre l’ « intérieur » et l’ « extérieur » de l’application. La règle à laquelle se plier est que le code qui s’occupe de la partie « intérieure » ne devrait pas déborder sur la partie « extérieure ».
Mettons de côté pour l’instant l’asymétrie gauche-droite ou haut-bas, nous voyons alors que l’application communique avec des agents externes à travers des « ports ». Le mot « port » est supposé vous évoquer, par analogie, le concept de ports des systèmes d’exploitation, dans lesquels tout périphérique respectant les protocoles d’un port peut y être branché ; il en est de même pour tout appareil électronique où là aussi tout périphérique compatible avec les protocoles mécaniques et électroniques d’un port peut y être branché.
- Le protocole d’un port est défini par le but de la conversation entre deux appareils.
Le protocole prend la forme d’une interface de programmation d’application (API).
Pour chaque périphérique externe existe un « adaptateur » qui convertit la définition de l’API en signaux nécessaires à la bonne communication avec le périphérique et vice versa. Un interface homme-machine (IHM) est un exemple d’adaptateur qui convertit grâce à l’API du port les mouvements de la souris faits par un utilisateur. Parmi les autres adaptateurs qui peuvent se brancher sur le même port, citons les outils de tests automatisés tels que FIT ou Fitness, les outils de gestion de batchs, et bien sûr tout code permettant de faire communiquer différentes applications entre elles au sein ou à l’extérieur de l’entreprise.
Passons à une autre partie de l’application, imaginons que celle-ci communique avec une entité externe pour obtenir des données. Le protocole utilisé est généralement un protocole de base de données. Du point de vue de l’application, si la source de données change d’une base de données SQL à un fichier plat ou à n’importe quel autre type de base de données, la conversation qui se fait avec elle à travers l’API ne devrait pas changer. Des adaptateurs supplémentaires pour ce même port devraient donc inclure un adaptateur SQL, un adaptateur fichier plat et plus important encore un adaptateur vers une base de données « mock 3» (comme par exemple une base de données résidente en mémoire) et ne devraient donc pas dépendre de l’existence d’une vraie base de données.
La plupart des applications possèdent seulement deux ports : le premier permettant de dialoguer du côté utilisateur, le second du côté base de données. Cela leurs donne une apparence asymétrique ; il est donc logique, du moins en apparence, de vouloir mettre en place une architecture à une, deux, trois, quatre voire cinq couches.
Il existe deux problèmes avec ces représentations. Le premier et sans doute le pire est que les gens ont tendance à ne pas prendre au sérieux les « frontières » qui figurent sur la représentation des couches de l’architecture. Ils ont tendance à laisser la logique applicative empiéter au-delà de ses propres frontières, provoquant ainsi les problèmes mentionnés précédemment. Le deuxième, c’est qu’il y a peut-être, en réalité, plus que deux ports pour l’application, de telle sorte que l’architecture telle qu’imaginée au départ ne tient pas dans une représentation à une dimension.
L’architecture hexagonale, ou architecture ports et adaptateurs, résout ces problèmes simplement en faisant le constat de l’existence de cette symétrie dans ce genre de situation : à savoir que l’application à l’intérieure communique avec le monde extérieur à travers un certain nombre de ports. Les éléments figurant à l’extérieur de l’application peuvent être gérés de manière symétrique.
La forme de l’hexagone a été choisie car elle permet visuellement de mettre en avant
(a) l’asymétrie intérieure-extérieure et la nature similaire des ports de telle sorte que cela permet de s’affranchir des représentations en couche à une dimension et de ce que cela induit
(b) la présence d’un nombre défini de ports - deux, trois, ou quatre (quatre étant le nombre le plus fréquent que j’ai pu observer jusqu’à présent)
L’hexagone a été choisi non pas parce que le nombre six est important, mais plutôt parce qu’il permet aux gens de faire une représentation avec suffisamment d’espace pour y faire figurer les ports et les adapteurs dont ils ont besoin, de ne pas être restreint par une représentation à une dimension. L’expression « architecture hexagonale » provient de cette volonté d’avoir cet effet visuel.
Le terme « ports et adapteurs » s’appuie sur la nature même des « finalités » représentées sur le dessin. Un port représente une conversation définie. Il y a en général plusieurs adaptateurs pour un port donné, différentes technologies peuvent être branchées sur ce port, comme par exemple un répondeur téléphonique, une voix humaine, un téléphone fixe, une interface homme-machine, une suite de tests, un outil de gestion des traitements batchs, une interface http, une interface directe programme-à-programme, une base de données « mock » (en mémoire), une « vraie » base de données (peut-être même plusieurs bases de données, l’une en environnement de développement, une autre pour l’environnement de test et une autre encore pour l’environnement de production).
Dans l’application Notes que nous verrons après, l’asymétrie gauche-droite sera remise en évidence. Toutefois, l’objectif premier de ce pattern 4 est de mettre en avant l’asymétrie interne-externe en évoquant brièvement que tous les éléments externes sont identiques du point de vue de l’application.
Structure
Illustration 2 : Architecture hexagonale avec adaptateurs.png

L’illustration 2 représente une application avec deux ports actifs et pour chacun d’eux plusieurs adaptateurs. Ces deux ports représentent respectivement le côté relatif au contrôle de l’application et celui relatif à la récupération de données. Cette représentation démontre que l’application peut être pilotée indifféremment par un automate, par une suite de tests de non-régression au niveau système, par un être humain, par une application à distance en mode http, ou par une autre application en local. Du côté données, l’application peut être configurée pour s’exécuter découplée de toute base de données externes en utilisant une base de données en mémoire (un « mock »), ou encore une base de données de remplacement ; elle peut s’exécuter aussi avec une base de données de test ou de production. Les spécifications fonctionnelles de l’application, qui peuvent être faites sous la forme de cas d’utilisations, décrivent les interfaces de la partie interne de l’hexagone et non les technologies externes pouvant être utilisées.
Illustration 3 : Image de l’architecture hexagonale architecture dite de la porte de grange.gif
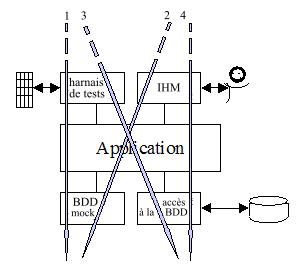{kind=link}

L’illustration 3 représente la même application selon une architecture en 3 couches. Pour simplifier l’illustration, seuls deux adaptateurs sont montrés pour chacun des ports représentés. Cette représentation illustre comment un ensemble d’adaptateurs s’intègrent dans les couches hautes et basses de l’application ainsi que la séquence d’utilisation des adaptateurs lors du développement du système. Les flèches numérotées montrent l’ordre dans lequel une équipe pourrait développer et utiliser une telle application :
- À l’aide d’une suite de tests FIT pilote l’application et utilise une base de données « mock » (c’est-à-dire en mémoire) qui se substitue à la vraie base de données ;
- Puis en ajoutant une IHM à l’application tout en continuant d’utiliser la « fausse » base de données ;
- Lors des tests d’intégration, des scripts de tests automatisés (à l’aide par exemple de Cruise Control) pilotent l’application connectée à la vraie base de données qui contient de données de tests ;
- En condition d’utilisation réelle, avec une personne utilisant l’application connectée à la vraie base de données avec de vraies données
Exemple de code
L’exemple d’application de calcul de remise commerciale ci-dessous, illustre de la manière la plus simple possible ce qu’est concrètement l’architecture ports et adaptateurs. Elle est accompagnée de la documentation FIT qui va bien.
discount(amount) = amount * rate(amount);
Dans notre adaptation, le montant est fourni par l’utilisateur et le taux par une base de données, il y a donc deux ports. Nous les implémentons en plusieurs étapes :
- D’abord avec des tests sur la base d’un taux constant à la place d’une base de données « mock »,
- ensuite avec une IHM,
- ensuite avec une base de données « mock » qui pourra être remplacée par une véritable base de données.
Je tiens à remercier Gyan Sharma d’IHC de m’avoir fourni le code de cet exemple.
Étape 1: FIT App un-taux-constant-à-la-place-d’une-base-de-données
D’abord nous créons le cas de test sous la forme d’une table HTML (cf. documentation FIT pour plus d’informations à ce sujet)
| TestDiscounter | |
| amount | discount() |
| 100 | 5 |
| 200 | 10 |
Il est intéressant de remarquer que les noms des colonnes deviendront les noms des classes et des fonctions dans notre programmes. Il existe différentes manières de faire dans FIT pour ne pas avoir à faire ces « programmeries », mais pour cet article nous mettrons cela de côté.
Sachant dorénavant ce que vont être les données de tests, nous allons créer l’adaptateur côté utilisateur et utiliser la fixture3 ColumnFixture disponible dans FIT :
import fit.ColumnFixture;
public class TestDiscounter extends ColumnFixture
{
private Discounter app = new Discounter();
public double amount;
public double discount()
{ return app.discount(amount); }
}
C’est tout ce qu’il y a à faire pour l’adapteur. Nous allons ensuite exécuter les tests à partir de la ligne de commande (consultez la documentation FIT pour adapter cette commande à votre environnement). Dans notre cas, voici ce que nous allons utiliser :
set FIT_HOME=/FIT/FitLibraryForFit15Feb2005
java -cp %FIT\_HOME%/lib/javaFit1.1b.jar;%FIT\_HOME%/dist/fitLibraryForFit.jar;src;bin
fit.FileRunner test/Discounter.html TestDiscount_Output.html
FIT produit un fichier comportant des codes couleurs nous montrant les tests ayant réussis (ou échoués au cas où nous aurions fait une erreur de frappe en cours de route.)
À ce stade, le code est prêt à être enregistré dans votre processus d’intégration continue (Cruise Control ou autre), et à être ajouté à votre chaîne de compilation et de test.
Étape 2 : IHM App un-taux-constant-à-la-place-d’une-base-de-données
Le code étant un peu long à faire figurer ici dans son intégralité, je vais vous laisser créer votre propre IHM pour l’application Discounter.
Pour vous aider, voici quelques-uns éléments-clés que doit contenir votre code :
...
Discounter app = new Discounter();
public void actionPerformed(ActionEvent event)
{
...
String amountStr = text1.getText();
double amount = Double.parseDouble(amountStr);
discount = app.discount(amount));
text3.setText( "" + discount );
...
}
À ce stade, une démonstration de l’application peut être faite ainsi qu’un test de régression. Les adaptateurs du côté utilisateurs sont tous opérationnels.
Étape 3 (FIT ou IHM) APP fausse base de données
Pour créer un adaptateur remplaçable du côté base de données, nous créons une « interface » vers un dépôt, et plus précisément vers un générateur de dépôt (« RepositoryFactory ») qui produira soit une base de données de type « mock » soit une véritable base de données.
public interface RateRepository
{
double getRate(double amount);
}
public class RepositoryFactory
{
public RepositoryFactory() { super(); }
public static RateRepository getMockRateRepository()
{
return new MockRateRepository();
}
}
public class MockRateRepository implements RateRepository
{
public double getRate(double amount)
{
if(amount <= 100) return 0.01;
if(amount <= 1000) return 0.02;
return 0.05;
}
}
Pour insérer cet adaptateur dans l’application Discounter, nous devons mettre à jour l’application elle-même afin qu’elle puisse prendre en compte l’utilisation de l’adaptateur repository et que l’adaptateur côté utilisateur (que ce soit FIT ou une IHM) passe le dépôt (« repository ») en paramètre à utiliser (la vraie ou la fausse (« mock ») base de données) au constructeur de l’application. Vous trouverez ci-dessous l’application mise à jour ainsi qu’un adaptateur FIT qui passe un faux dépôt (le code de l’adaptateur FIT permettant de choisir de passer l’adapteur vers le vrai ou le faux dépôt est lui aussi trop long tout en n’apportant pas grand-chose en terme d’informations, je ne l’ai donc pas inclus dans la version ci-dessous).
import repository.RepositoryFactory;
import repository.RateRepository;
public class Discounter
{
private RateRepository rateRepository;
public Discounter(RateRepository r)
{
super();
rateRepository = r;
}
public double discount(double amount)
{
double rate = rateRepository.getRate( amount );
return amount * rate;
}
}
import app.Discounter;
import fit.ColumnFixture;
public class TestDiscounter extends ColumnFixture
{
private Discounter app =
new Discounter(RepositoryFactory.getMockRateRepository());
public double amount;
public double discount()
{
return app.discount( amount );
}
}
Ceci conclut l’implémentation de la version la plus simple possible de l’architecture hexagonale.
Vous pouvez consulter sur cette page une implémentation différente de l’architecture hexagonale à base de Ruby et de Rack
Notes de l’application
L’asymétrie gauche-droite
Le pattern ports & adapters est écrit délibérément en partant du postulat que tous les ports sont foncièrement similaires. Ce postulat est utile à un niveau architectural. En termes d’implémentation, les ports et les adapters peuvent être de deux ordres, que j’appellerai respectivement « primaire » et « secondaire » pour des raisons qui vous paraîtront bientôt évidentes. Il est également possible de les appeler adapters « pilote » et « piloté »
Le lecteur avertit aura remarqué que dans tous les exemples donnés des fixtures FIT sont utilisés pour les ports côté gauche et des mocks côté droit. Dans une architecture en 3 couches, FIT se situe au niveau le plus haut alors que le mock est au niveau le plus bas.
Ceci est à rapprocher de l’idée d’« acteurs primaires » et d’« acteurs secondaires » issues des cas d’utilisation. Un « acteur primaire » est un acteur qui pilote l’application (autrement dit de la faire sortir de son état de veille pour exécuter une des fonctions présentes). Un « acteur secondaire » quant à lui se voit piloté par l’application, soit pour en obtenir des informations soit pour simplement émettre une notification. La distinction entre « primaire » et « secondaire » repose sur qui va déclencher ou qui est en charge de la conversation.
L’adaptateur de test pour substituer un acteur « primaire » est tout naturellement FIT, ce framework étant conçu pour lire un script et piloter l’application. L’adaptateur de test pour substituer un acteur « secondaire » comme, par exemple, une base de données est tout naturellement un mock, étant donné qu’il est conçu pour répondre à des requêtes ou pour enregistrer les évènements de l’application.
Ces observations nous conduisent à suivre le diagramme de contexte des cas d’utilisation du système et à dessiner les « ports primaires » et les « adaptateurs primaires » du côté gauche (ou en haut) de l’hexagone et les « ports secondaires » et les « adaptateurs secondaires » sur le côté droit (ou bas) de l’hexagone.
Les relations entre ports & adapters primaires et secondaires et leurs implémentations respectives avec FIT ou à l’aide de mocks est quelque chose d’important à garder à l’esprit, mais elles devraient être utilisées comme étant une conséquence de l’utilisation de l’architecture ports & adapters, et non pour prendre un raccourci. Le bénéfice ultime d’une implémentation ports & adapters est la capacité d’exécuter l’application en mode isolé.
Cas d’utilisation et frontières de l’application
L’utilisation du pattern de l’architecture hexagonale permet de réaffirmer sur quelle est la manière privilégiée de rédiger les cas d’utilisation.
Une erreur assez répandue dans l’écriture des cas d’utilisation est de vouloir y mettre une connaissance implicite de la technologie utilisée en dehors des ports. Ces cas d’utilisations ont gagné à juste titre une mauvaise réputation dans l’industrie informatique comme étant trop longs, difficiles à lire, ennuyeux, peu fiables et coûteux à maintenir.
Si l’on réfléchit bien à l’architecture ports & adapters , nous pouvons voir que les cas d’utilisation devraient être écrit à l’intérieur des limites de l’application (autrement dit la partie interne de l’hexagone) pour spécifier les fonctions et les évènements supportés par l’application, et ce, quel que soit la technologie externe derrière. Dans ces conditions, les cas d’utilisations peuvent être plus courts, plus facile à lire, moins coûteux à maintenir et pérenne.
Combien de ports ?
Qu’est-ce qu’exactement un port ou ce qu’il n’est pas est largement une question de goût. D’un côté du spectre, chaque cas d’utilisation pourrait avoir son propre port, ce qui donnerait des centaines de ports pour différentes applications. De l’autre côté, on pourrait imagine fusionner tous les ports primaires et tous les ports secondaires de telle sorte qu’il n’y ait plus que deux ports, l’un du côté gauche et l’autre de côté droit.
Aucun de ces deux extrêmes ne s’avèrent optimal.
Le système météo, décrit dans cette partie des cas d’usages connus, possède quatre ports dits naturels : le flux météo, l’administrateur, les souscripteurs notifiés, la base de données souscriptrice. Un contrôleur de machine à café a quatre ports naturels : l’utilisateur, la base de données contenant les recettes et les prix, les distributeurs et le monnayeur. Un système pharmaceutique dans un hôpital pourrait en avoir trois : un pour l’infirmière, un pour la base de données des prescriptions, et un pour l’ordinateur pilotant la distribution de médicaments
À priori, il n’y a aucun risque particulier à se tromper à faire un « mauvais » choix du nombre de ports, cela reste une question d’intuition. J’ai tendance à favoriser un petit nombre de ports, deux, trois ou quatre ports comme évoqué précédemment et également ci-dessous dans les cas d’usages connus.
Cas d’usages connus
Illustration 4 : Exemple complexe de l’architecture hexagonale.png

L’illustration n°4 montre une application comportant quatre ports et pour chacun d’eux plusieurs adaptateurs. Cette illustration a été faite sur la base d’une application de surveillance relative aux alertes sismiques, tornades, incendies et inondations provenant du service de météorologie nationale, et qui, lorsqu’elles se produisent, notifie les populations sur leur téléphone ou sur leur répondeur. À l’époque où nous discutions de ce système, les interfaces de celui-ci étaient identifiées et abordées par « technologie, liées à leur objectif premier ». Autrement dit, il y avait une interface pour le déclencheur de données arrivant par le réseau filaire, une pour les données de notification à envoyer aux répondeurs, une interface pour l’IHM d’administration et une interface pour la base de données stockant les données des abonnés.
Les gens se tiraient les cheveux parce qu’ils devaient ajouter une interface http pour le service météorologique ainsi qu’une interface pour les courriels à destination des abonnés, et ils devaient aussi trouver une manière d’empaqueter et de désempaqueter leur suite applicative qui grossissait pour satisfaire les préférences de ses différents clients. Ils craignaient d’être bloqués lors d’une maintenance sans compter que les tests des nouvelles fonctionnalités devenaient un véritable cauchemar car ils devaient implémenter, tester et maintenir toutes les différentes versions demandées par leurs clients.
Les changements apportés en termes de conception a été d’une part d’élaborer les interfaces du système « par objectif » plutôt que par technologie, et d’autre part de faire en sorte que les technologies soient substituables (peu importe le côté) au niveau de chaque adaptateur. Ils ont alors immédiatement eu la possibilité d’inclure le flux http et la notification par courriel (les nouveaux adaptateurs sont identifiables sur l’illustration avec les lignes en pointillés). En rendant chaque application exécutable en mode headless à travers des API, ils ont pu à la fois ajouter un adaptateur « application-prêt-à-ajouter » et désempaqueter la suite applicative, permettant ainsi d’y connecter des sous-applications à la demande. Enfin, en rendant chaque application exécutable de manière isolée, à l’aide adaptateurs de tests, de mocks et de scripts de tests automatisés autonomes, ils ont ainsi acquis la capacité de faire des tests de non-régression de leurs applications.
Mac, Windows, Google, Flickr, Web 2.0
Au début des années 90, les applications Macintosh telles que les applications de traitement de texte devaient avoir des interfaces pilotables par API, afin que d’autres applications ou des scripts faits par des utilisateurs puissent accéder à l’ensemble des fonctionnalités des applications. Les applications de bureau sur Windows ont depuis évolué pour avoir les mêmes possibilités (à défaut de connaissances historiques suffisantes, j’ignore laquelle de ces deux plateformes a eu cette possibilité en premier, mais ce n’est pas important dans le cadre de cet article).
La tendance actuelle (en 2005) pour les applications web est de mettre à disposition une API et de permettre à d’autres applications web ainsi d’y accéder directement. Par exemple, il est possible de diffuser des données relatives aux crimes locaux sur une carte Google ou de créer des applications web qui incluent les fonctionnalités de Flickr d’archivage et d’annotations de photos.
Tous ces exemples portent sur le fait de rendre visible les API des « ports primaires ». Ils n’évoquent en rien l’existence de ports secondaires.
Sorties stockées
L’exemple ci-dessous a été écrit par Willem Bogaerts sur le wiki C2 :
« J’ai déjà été confronté par le passé à quelque chose de similaire, mais à l’époque c’était dû principalement à ma couche applicative qui avait fini à gérer des choses qu’elle n’avait pas vocation à gérer - en gros elle ressemblait à un véritable central téléphonique à l’ancienne. Mon application générait la sortie, la montrait à l’utilisateur et avait aussi la possibilité de la stocker. Le problème … mon problème étant qu’il n’était pas toujours nécessaire de la stocker. Donc mon application générait la sortie vers un tampon et la présentait à l’utilisateur. Celui-ci décidait alors s’il voulait la stocker, l’application la récupérait alors du tampon et la stockait pour de vrai.
En fait, cette situation ne me plaisait pas du tout. Puis je suis arrivé à une solution : mettre en place un contrôle de la (couche de) présentation avec des capacités de stockage. Aujourd’hui l’application n’oriente plus la sortie vers tel ou tel endroit, mais elle l’envoie au contrôle de la présentation. C’est ce dernier qui met en tampon la réponse et donne à l’utilisateur la possibilité de la stocker.
L’architecture traditionnelle en couche insiste pour que « l’IHM » et le « stockage » soient différents. L’architecture Ports & Adapters est en mesure restreindre la sortie de telle manière à ce qu’elle redevienne à nouveau simple « sortie » ».
Exemple anonyme extrait du wiki C2
« Sur l’un des projets que j’ai travaillés, nous avons utilisé le _SystemMetaphor_ pour un composant système stéréo. Chaque composant comportait des interfaces définies, chacune ayant un but spécifique. Nous avons été alors en mesure d’y connecter plusieurs composants ensemble pour ainsi dire de manière quasi-illimitée en utilisant simplement des câbles et des adaptateurs. »
Développement avec des équipes de grande taille distribuées
Ce cas d’usage de l’architecture hexagonale est en cours d’évaluation et ne peut donc pas être tout à fait considéré comme une utilisation éprouvée de ce pattern. Toutefois, il est intéressant de regarder en quoi il consiste.
Dans ce cas d’usage, les équipes sont réparties sur différents lieux géographiques, elles élaborent ensemble une solution logicielle à l’aide de l’architecture hexagonale à l’aide de FIT et de mocks afin que les applications ou les composants puissent être testés de manière indépendante. La compilation avec CruiseControl est faite toutes les demi-heures sur l’ensemble des applications à l’aide de la combinaison FIT + mock. Au fur et à mesure que le sous-système applicatif et les sous-systèmes de bases de données sont terminés, les mocks sont remplacés par de « vraies » bases de données de test.
Séparer le développement de l’IHM et de la partie applicative.
Ce cas d’usage de l’architecture hexagonale en est au tout début de son évaluation et ne peut donc pas vraiment être considéré comme une utilisation éprouvée de ce pattern. Regardons, lui aussi, en quoi il consiste.
Dans celui-ci, aucune décision n’avait été prise (au lancement du projet - NdT) tant au niveau de la technologie à utiliser qu’au niveau de la métaphore de navigation, par conséquent la conception de l’IHM s’avère pour l’instant immature. L’architecture des services côté back-end n’est non plus décidée pour l’instant et il y a de fortes chances que tout cela changera plusieurs fois dans les 6 mois à venir. Toutefois, le projet est officiellement lancé et l’horloge tourne.
L’équipe du côté logique applicative a créé des tests FIT et des mocks pour isoler l’application et créer des fonctionnalités testables et démontrables à ses utilisateurs. Lorsque les décisions concernant l’IHM et les services seront finalement prises, cela « ne devrait être qu’une formalité » d’ajouter ces éléments à l’application. Tenez-vous au courant en venant lire ici pour savoir comment cela avance (ou essayez vous-même de votre côté et écrivez-moi). Je vous invite à revenir régulièrement consulter cette partie si vous désirez savoir comment elle avance (ou vous pouvez aussi essayer de votre côté et m’écrire par la suite pour m’informer de vos propres travaux).
Patterns liés
Adapter
L’ouvrage « Design Patterns » comporte la description d’un pattern « Adapter » générique : « Convertir l’interface d’une classe en une autre interface que les clients attendent ». Le pattern Ports & Adapters est une utilisation spécifique du pattern « Adapter ».
Modèle - Vue - Contrôleur
L’implémentation la plus ancienne connue du pattern MVC a été en 1974 dans un projet Smalltalk. Il a connu au cours des années différentes variations, comme les patterns Model-Interactor et Model-View-Presenter. Toutes ces variations implémentent l’idée des ports primaires du pattern Ports & _Adapters_ mais pas celle des ports secondaires.
Objects Mocks et Loopback (rebouclage)
« Un objet mock est un “ agent double ”, il est utilisé pour tester le comportement d’autres objets. Tout d’abord un objet mock se comporte comme une fausse implémentation d’une interface ou d’une classe et en imite son comportement extérieur. Ensuite, un objet mock observe comment les autres objets interagissent avec ses méthodes et comparent le comportement observé avec le comportement attendu pré paramétré. Lorsqu’une divergence apparaît, un objet mock peut interrompre le test et rapporter l’anomalie. Si la divergence ne peut être rapportée lors des tests, un appel de méthode de vérification effectué par le testeur s’assurera alors que tous les attendus aient été atteints ou que les anomalies aient été rapportées » — extrait de la page http://MockObjects.com
Si les mocks sont implémentés conformément à ce qui avait été prévu, ceux-ci peuvent être utilisés (à part entière - NdT) au sein de l’application, et pas uniquement en tant qu’interfaces externes. Le périmètre initial des objets mock est de se conformer au protocole spécifié au niveau d’une classe donnée ou d’un objet donné. Je me suis permis d’emprunter leur mot mock car il s’agit de la description qui correspond le mieux à un substitut en mémoire pour un acteur secondaire externe.
Le pattern Loopback est un pattern explicite pour remplacer en interne un périphérique externe.
Pattern Pedestals (piédestal)
Dans son ouvrage « Patterns for Generating a Layered Architecture », Barry Rubel décrit un pattern permettant de créer un axe de symétrie pour contrôler un logiciel très similaire au pattern Ports & Adapters. Le pattern Pedestal incite à implémenter un objet représentant un périphérique matériel au sein du système et à lier ces objets ensemble dans une couche de contrôle. Le pattern Pedestal peut être utilisé pour décrire les deux côtés (interne et externe) de l’architecture hexagonale, mais il n’insiste pas sur la similarité au niveau des adapters. De plus, il a été écrit dans le cadre d’un environnement de contrôle industriel, il n’est pas évident de prime abord de voir comment il peut s’appliquer à des applications informatiques.
Vérifications
Le langage de pattern développé par Ward Cunningham pour détecter et gérer les erreurs de saisies des utilisateurs s’avère particulièrement bien adapté pour gérer les erreurs traversant les frontières de l’hexagone interne.
Inversion de dépendance (injection de dépendance) et SPRING
Le principe d’inversion de dépendance de Bob Martin (appelé également injection de dépendance par Martin Fowler) définit que « les modules de haut niveau ne devraient pas dépendre de modules de bas niveau. Les deux devraient dépendre d’abstractions. Les abstractions ne devraient pas dépendre de détails. Les détails devraient dépendre d’abstractions ». Le pattern d’ « injection de dépendance » de Martin Fowler donne quelques exemples d’implémentations. Ces derniers montrent comment créer des adaptateurs d’acteurs secondaires interchangeables. Le code peut être saisit directement, tel que cela est fait dans l’exemple de code dans cet article, ou utilisé via des fichiers de configuration puis le code équivalent est généré via le framework SPRING.
Remerciements
Je tiens à remercier Gyan Sharma d’Intermountain Health Care pour m’avoir fourni les exemples de code présents dans cet article. Je remercie également Rebecca Wirfs-Brock pour son ouvrage « Object Design » qui conjugué à la lecture du pattern « Adapter » dans l’ouvrage « Design Pattern » m’a aidé à comprendre ce qu’était l’architecture hexagonale. Merci aussi à toutes les personnes qui via le wiki de Ward m’ont donné de précieux commentaires sur ce pattern ces dernières années (et tout particulièrement Kevin Rutherford).
Bibilographie et lectures recommandées
FIT, A Framework for Integrating Testing: Cunningham, W., disponible en ligne à l’adresse suivante http://fit.c2.com, ainsi que l’ouvrage « Fit for Developing Software », aux éditions Prentice-Hall PTR, 2005 par Mugridge, R. et Cunningham, W.,
Le pattern « Adapter » figure dans l’ouvrage « Design Patterns », Addison-Wesley, 1995, pp. 139-150. par Gamma, E., Helm, R., Johnson, R., Vlissides, J.,
Le pattern « Pedestal » évoqué par Rubel, B. évoqué dans son ouvrage , et aussi dans « Patterns for Generating a Layered Architecture » écrit par , par Coplien, J., Schmidt, D., « PatternLanguages of Program Design », Addison-Wesley, 1995, pp. 119-150.
Le pattern « Checks » de W. Cunningham, W., disponible en ligne à l’adresse suivante http://c2.com/ppr/checks.html
Le « Principe d’inversion de dépendance » évoqué dans l’ouvrage « Agile Software Development Principles Patterns and Practices » de Robert C. Martin, Prentice Hall, 2003, dans le chapitre 11 « The Dependency-Inversion Principle » ainsi qu’en ligne sur la page http://www.objectmentor.com/resources/articles/dip.pdf
Le pattern d’ « Injection de dépendance » de M. Fowler disponible en ligne à l’adresse suivante http://www.martinfowler.com/articles/injection.html
Le pattern « Mock Object » de S. Freeman, S. disponible en ligne à l’adresse suivante http://MockObjects.com
Le pattern « Loopback » d’A. Cockburn disponible en ligne à l’adresse suivante http://c2.com/cgi/wiki?LoopBack
Les « cas d’utilisation » expliqués en détail dans « Rédiger des cas d’utilisation efficaces » par A. Cockburn, Addison-Wesley, 2001, ainsi que dans Cockburn, A.,« Structurer les cas d’utilisation à l’aide de buts », disponible en ligne à l’adresse suivante http://alistair.cockburn.us/crystal/articles/sucwg/structuringucswithgoals.htm
Commentaires provenant de l’ancien site :
Dans un de ses articles sur son blog While True André Boonzaaijer évoque une application élaborée avec l’ architecture hexagonale (discussion: Re: Hexagonal architecture)
Kevin Rutherford a écrit plusieurs articles sur l’architecture hexagonale que vous pouvez retrouver sur les pages suivantes :
Gravity and software adaptability
Hexagonal architecture
Databases as life-support for domain objects
Hexagonal soup
Timo a écrit ce bref article intitulé Wrap it thinly sur l’utilisation de l’architecture hexagonale conjointement avec le développement piloté par les tests.
Dans son ouvrage traitant des patterns Xunit Gerard Meszaros y évoque l’architecture hexagonale que vous pouvez retrouver à l’adresse suivante : http://xunitpatterns.com/Hexagonal%20Architecture.html.
Brian Anderson a écrit plusieurs articles de blog sur le sujet de l’architecture hexagonale dont voici les liens :
Success! - lien introuvable NdT
Problems with Smart Clients today - lien introuvable NdT
compile time vs runtime views - lien introuvable NdT
the use of symmetry in the hexagonal approach
Back to Hexagonal Architecture
some thoughts on the “Design Pattern” pattern
http://www.brianmandersen.com/blog/page/2/
La page d’origine sur l’architecture hexagonale est disponible sur le wiki de Ward Cunningham à l’adresse suivante http://c2.com/cgi/wiki?HexagonalArchitecture
Utah Code Camp Sept 19, 2009 : mission codage
L’application de calcul de remise commerciale,illustre de la manière la plus simple possible ce qu’est concrètement l’architecture ports et adaptateurs. Il est fourni avec la documentation FIT qui va bien.
discount(amount) = amount * discountRate(amount);
- La variable
amountest saisie par l’utilisateur ou provient du framework de test (ou d’un fichier) - La variate
rateprovient d’une base de données ou d’une base de données mock en mémoire
L’implémentation suit les étapes suivantes :
- Les données en entrée proviennent du framework de test, une constante est utilisée pour le taux
discountRate. - Les données en entrée sont saisies via une IHM, le taux
discountRateest toujours une constante. - Les données en entrée proviennent soit des tests soit d’une IHM, le taux
discountRateprovient d’une base de données mock qui peut être dans le futur échangée avec une vraie base de données.
Implémentation en Ruby / Rack (sans Rails)
J’ai fait une petite version web de cette application que vous pouvez consulter à l’adresse suivante https://github.com/totheralistair/SmallerWebHexagon
Celle-ci utilise du côté gauche un navigateur, un pilote Rack ou simplement un pilote de test et du côté droit une constante, du code ou un fichier de base de données. Je l’ai écrite en 2014 pour montrer une implémentation simple mais concrète de cette architecture.
Autres discussions et implémentations
Vous pouvez bien sûr trouver d’autres ressources à propos de l’architecture hexagonale en cherchant via Google ou via Twitter notamment. Vous pouvez aussi consulter :
- Cet article de Thierry Pierrain http://tpierrain.blogspot.fr/2013/08/a-zoom-on-hexagonalcleanonion.html
- Le support de la présentation que j’ai pu donner à l’Utah Code http://alistair.cockburn.us/Hexagonal+Architecture+Keynote+at+Utah+Code+Camp+September+2009.pps
- une autre axe de présentation de l’architecture hexagonale fait par Duncan Nisbet sous l’angle de prises de notes faites à sa propre intention [http://www.duncannisbet.co.uk/hexagonal-architecture-for-testers-part-1](https://web.archive.org/web/20220517045625/https://www.duncannisbet.co.uk/hexagonal-architecture-for-testers-part-1
- Une courte vidéo d’une présentation que j’ai donné lors de la conférence Mountain West Ruby en 2010: Video of Alistairs hexagonal architecture CQRS lightning talk Mountain West Ruby Conference 2010 (discussion: Re: Video of Alistairs hexagonal architecture CQRS lightning talk Mountain West Ruby Conference 2010)
- en recherchant directement sur Twitter à l’aide de ce lien https://twitter.com/search?q=%22hexagonal%20architecture%22
- ce tweet http://twitter.com/andrzejkrzywda/status/267420878487310336
- ce minuscule CMS implémentant l’architecture hexagonale (avec uniquement un port du côté utilisateur) https://github.com/totheralistair/SmallWebHexagon
- Pat Maddox a fait un autre exemple intégrant architecture hexagonale, programmation évènementielle et le pattern CQRS https://github.com/patmaddox/hexarch2. Jetez-y un coup d’œil.
- Un très bel échange vidéo sur l’architecture hexagonale et Rails entre BadrinathJanakiraman et Martin Fowler: http://thoughtworks.wistia.com/medias/uxjb0lwrcz
- le récit d’une réflexion sur https://github.com/Lunch-box/SimpleOrderRouting/wiki/Logbook-4#day-15-october-27th-2014
Dépendances configurables, acteurs primaires et secondaires
(Lorsque j’ai imaginé ce pattern - NdT) j’ai essayé de faire en sorte que ce pattern soit vraiment symétrique, d’où l’hexagone. Toutefois en regardant plusieurs de ses implémentations, il est devenu clair avec le temps qu’il existe une asymétrie (ce qui rend l’architecture hexagonale fondamentalement différentes des autres patterns comme l’architecture en oignon). Cette asymétrie décrite précédemment (cf. l’asymétrie gauche-droite) rejoint le concept d’Ivar Jacobson d’acteurs primaires et secondaires et impacte la manière dont la Dépendance Configurable peut être implémentée comme nous pouvons le deviner sur ce dessin :

Configurable Dependency illustrated1-800pxV.jpg (discussion: Re: Configurable Dependency illustrated1-800pxV.jpg)
Cette différence entre acteur primaire et secondaire repose uniquement sur lequel des deux acteurs initie la conversation. Un acteur primaire connait le propos de cette conversation et l’initie avec le système ou l’application ; pour un acteur secondaire, c’est le système ou l’application qui connait le propos et qui initie la discussion avec autrui. C’est en réalité la seule différence entre les deux, du moins, au pays des cas d’utilisation en tout cas.
Au niveau de l’implémentation, cette différence est importante : quiconque initiera la conversation doit passer le relais à l’autre.
Dans le cas des ports de l’acteur primaire, le constructeur macro devra passer le relais à l’IHM, le framework de test ou au pilote de l’application et lui dire « allez, parle-lui ». L’acteur primaire parlera alors à l’app et l’app ne saura probablement jamais qui l’a appelé. (Ce qui est normal du point de vue des destinataires d’un appel).
En contraste, dans le cas des ports de l’acteur secondaire, le constructeur macro devra passer le relais à l’IHM, le framework de test ou au pilote à l’acteur secondaire identifié passé en paramètre à l’application, et c’est l’application qui saura désormais qui/quel est le destinataire de l’appel sortant. (Ce qui est là aussi normal lorsque l’on émet un appel).
Par conséquent, le système ou l’application sera construite différemment pour les ports des acteurs primaires et secondaires : d’une part ignorante et initialement passive pour les acteurs primaires et d’autre part avoir une manière de stocker et d’appeler les ports des acteurs secondaires.
Ces deux types de ports implémentent la Dépendance Configurable (discussion: Re: Configurable Dependency), mais de manière différente.
Voici un exemple simple d’un système à 3 ports comme une machine à café, une unité médicale de distribution par intraveineuse (cela paraît vraiment étrange d’ailleurs que les deux partagent la même architecture)
- L’acheteur, l’harnais de test ou l’administrateur de l’hôpital est l’acteur primaire qui pilote le système
- La base de données de recettes ou la base de données médicale est l’acteur secondaire qui délivre ses informations
- Le système de distribution (café ou médicamenteux) est dans les deux cas des acteurs secondaires.
En conclusion : l’aspect primaire / secondaire d’un port ne peut pas être ignoré
Vous pouvez aussi vous reporter à la FAQ Architecture hexagonale (discussion: Re: Hexagonal Architecture FAQ)
Auteur : Alistair Cockburn
Source : Hexagonal architecture
Date de parution originale : 04 Janvier 2005
Traducteur : Nicolas Mereaux
Date de traduction : 31/12/2023

Ce(tte) oeuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
-
Ports et adaptateurs ↩
-
littéralement sans tête c’est-à-dire sans interface utilisateur ↩
-
un mock simule l’existence d’un véritable service comme une base de données, on peut employer en français le terme de simulacre ↩ ↩2
-
un pattern est une structure, un modèle permettant de répondre à certaines problématiques connues ↩