LeSS - Intégration continue
« Portail LeSS < Portail Excellence Technique
Utiliser COBOL est un vrai traumatisme pour l’esprit ; son enseignement devrait, par conséquent, être considéré comme étant un crime. –Edsger Dijkstra
L’intégration continue (IC) est indispensable pour faire passer le développement lean et agile à grande échelle.
Notre conclusion est qu’il n’existe aucune raison intrinsèque qui pourrait expliquer pourquoi les processus d’intégration continue et de compilation automatisée ne pourraient pas s’adapter quelle que soit la taille d’équipe. En fait … [ils] deviennent plus essentiels que jamais. Magennis071
Grâce à l’intégration continue, les développeurs font grandir peu à peu un système stable en travaillant par petits lots et en cycles courts - un sujet lean. L’intégration continue permet aux équipes de travailler sur un code commun, d’augmenter le degré de visibilité au niveau du développement et le degré de qualité au niveau du système.
Il existe certains malentendus vis-à-vis de l’intégration continue ; cela semble être un concept simple, mais en pratique, ce n’est pas le cas. Écartons donc un malentendu tout de suite : l’intégration continue ce n’est ni l’automatisation de la compilation ni l’exécution des tests.
Pour citer un article bien connu sur l’intégration continue :
L’intégration continue est une pratique de développement logiciel dans laquelle chaque membre de l’équipe intègre son travail fréquemment, et de manière générale quotidiennement - ce qui a pour conséquence plusieurs intégrations par jour au niveau de l’ensemble de l’équipe.
Chaque intégration est vérifiée par une compilation automatisée (incluant les tests) afin de détecter les erreurs d’intégration le plus vite possible.
Les pratiques d’intégration continue
L’intégration continue c’est :
- une pratique de développeur …
- pour garder un système opérationnel
- par petites touches
- tout en le faisant grandir
- en faisant des opérations d’intégration au moins quotidiennement
- sur la ligne principale
- grâce au système d’intégration continue
- et beaucoup de tests automatisés
Une pratique de développeur
Les discussions à propos de l’intégration continue tournent trop souvent autour des outils et de l’automatisation. Bien que cela s’avère important, l’intégration continue est, par essence, une pratique de développeur. Owen Rogers, l’un des créateurs originaux de CruiseControl.NET2 déclare la chose suivante :
L’intégration continue est une pratique – il s’agit de ce que font les personnes, non pas des outils qu’ils utilisent. Lorsqu’un projet commence à grandir, il est facile d’être induit en erreur en pensant que l’équipe fait de l’intégration continue simplement parce que tous les outils sont paramétrés et opérationnels. Si les développeurs n’ont pas la discipline d’intégrer régulièrement leurs changements ou de maintenir leur environnement de développement en bon état de marche alors ils ne font pas d’intégration continue. Point barre. Rogers04
Fractionner les changements en petits incréments, les intégrer quotidiennement à minima, et avoir la discipline de ne pas casser la compilation, tout cela est fait par chaque développeur individuellement.
Chaque développeur doit être en capacité de travailler en petits incréments et pouvoir conserver sa propre copie du système (ou une partie du système) opérationnelle à tout instant.
Adopter l’intégration continue exige un changement de comportement. Nous avons travaillé au sein d’une organisation sur plusieurs gros produits avec un très bon outil de compilation automatisée mais les développeurs n’intégraient pas leur code fréquemment. En effet, partout le message “TU ne casseras PAS le fruit de la compilation” était proclamé haut et fort, en clouant au piloris, par exemple, les personnes qui auraient osé casser la compilation. Et qu’est-ce qui devait arriver ? Les développeurs retardaient leur intégration par peur de casser la compilation. En dépit d’un indicateur toujours au vert (toujours passant) de la compilation automatisée, ils faisaient l’exact inverse d’une démarche d’intégration continue.
Le développement piloté par les tests (ou TDD pour l’acronyme en vo - NdT) avec un refactoring (acte de remanier le code en vue de l’améliorer - NdT) constant aide beaucoup. Lorsqu’un développeur développe son code par des tests unitaires, il s’assure que sa copie locale est toujours en état de marche. Tous les tests passent tout le temps. En théorie, il est donc capable d’intégrer son code à chaque tour de cycle de TDD (environ toutes les dix minutes3 ; en pratique, il intègre tous les deux tours de cycle.
L’intégration continue sur de gros produits est difficile et tout particulièrement parce qu’il s’agit d’une pratique de développeur. S’il ne s’agissait seulement que d’outils et d’automatisation, vous pourriez commencer simplement un projet d’intégration continue ou faire appel à une entreprise pour “installer l’intégration continue”. Mais comme il s’agit d’une pratique de développeur, l’intégration continue exige un changement des habitudes quotidiennes de tous les développeurs. Cela s’avère difficile avec pas mal de personnes, cela prend du temps et cela demande de l’accompagnement.
Avec le bon comportement, les développeurs pourront ainsi s’organiser…
Pour garder un système opérationnel
De manière similaire au concept lean du jidoka, l’intégration continue veut dire avoir toujours un système stable. Lorsqu’un test échoue – qu’il ait été lancé localement ou sur le système d’intégration continue – le développeur le corrige immédiatement et par conséquent permet de conserver un système opérationnel et stable.
Une des caractéristiques du développement séquentiel traditionnel est d’avoir du travail en cours (TEC, WIP) non intégrés. Personne ne sait si les différentes parties de ce travail en cours fonctionnent ensemble ou s’ils sont exempts d’anomalies. Le TEC rend difficile de prévoir ce genre de chose quand, ou si, le système est livrable. L’intégration continue augmente la visibilité en supprimant ce TEC – en ayant toujours l’ensemble des parties intégrées – et cela permet d’avoir davantage de contrôle et de prévisibilité.
Note : L’intégration continue et le développement itératif et incrémental dans Scrum ont la même stratégie. Toutefois, l’intégration continue est sur une maille plus fine qu’une itération Scrum. Les deux permettent de réduire la variabilité, et le risque en travaillant par petits lots – itérativement.

James Shore, développeur agile et auteur de The Art of Agile Development [SW07] insiste sur le fait qu’il s’agit d’une pratique de développeur. Dans un très bon article intitulé Continuous Integration on a Dollar a Day [Shore06], James Shore explique comment faire de l’intégration continue avec un vieil ordinateur, un poulet en plastique, une clochette et un automate de compilation. La vieille machine de développement est utilisée comme machine d’intégration. Le poulet en plastique est le témoin d’intégration — seule la personne ayant le poulet en plastique peut intégrer son code. La clochette annonce une intégration réussie. Mais l’étape la plus importante dans cette description de l’intégration continue consiste à réunir tous les développeurs dans une seule pièce et de les faire se mettre d’accord pour “qu’à partir de maintenant, notre code qui est en gestion de configuration compilera toujours avec succès et passera les tests”.
Le poulet en plastique ne peut passer à grande échelle sur de gros produits. Ceci dit, cette histoire permet très clairement de se rappeler que l’intégration continue est une pratique de développeur.
Ce système opérationnel, évoluant en petits incréments, est créé par…
Par petits changements
Une fois, nous avons travaillé pour un groupe en Finlande produisant une passerelle et qui devait apporter un grand changement dans sa pile de protocoles. Le groupe insistait pour dire qu’il serait impossible de fractionner ce grand changement en plusieurs petits changements. Ils ont donc fait ce grand changement puis ont passé trois mois à essayer de faire fonctionner à nouveau le système. Après cette pénible expérience, ils ont été d’accord pour ne plus jamais faire d’aussi gros changements en une seule fois.
Faire de gros changements dans un système stable aura pour conséquence de le déstabiliser et de le casser de manière très importante. Plus gros sera le changement, plus il faudra de temps pour remettre le système dans un état stable.
Éviter donc les gros changements. À la place, fractionner chaque changement en petits changements – en appliquant le concept lean des petits lots. De cette manière chaque changement peut intègrer le système facilement.
Avec des petits changements vous pourrez faire …
Faisant grandir le système
Faire grandir versus construire est un changement d’état d’esprit important. Dans son célèbre article No Silver Bullet, Frederick P. Brooks médite sur son expérience passée :
La métaphore de la construction a survécu bien au-delà de son utilité première … Si, comme je le crois, les structures conceptuelles que nous construisons aujourd’hui sont trop compliquées pour être spécifiées précisément, et trop complexes pour être construites sans anomalie, alors il nous faut prendre une approche radicalement différente… Le secret est qu’un système doit grandir, non être construit … Harlan Mills a proposé que tout système logiciel devrait grandir via un développement incrémental … Rien au cours des dix dernières années n’a si radicalement changé que ma propre pratique, ou son efficacité … Les effets du point de vue du moral sont stupéfiants.
L’enthousiasme fait des bonds lorsque le système est opérationnel, même s’il s’agit d’un système simple … On a toujours, à chaque étape du processus, un système opérationnel. Je trouve que les équipes arrivent à faire grandir des entités beaucoup plus complexes en 4 mois que lorsqu’elles les construisent.
Construire un système implique construire les composants séparément et, lorsqu’ils sont finis, de les assembler ensemble. Faire grandir un système implique de le nourrir et le faire évoluer en un plus grand système (voir grandir versus construire).
Est-ce possible avec de gros systèmes ayant du code déjà existant ? Cette question nous est posée fréquemment. Dans presque tous les cas, la réponse est oui. Si vos développeurs ou vos architectes ne peuvent pas le faire ou clament que c’est impossible, vous pouvez interprétez cela comme un signe d’un manque de compétence.
Un développeur intègre de manière continue son travail lorsqu’il travaille sur une tâche. Il n’attend pas que la tâche ou que la fonctionnalité soit terminée pour la “jeter” dans le système. À la place, lorsqu’une petite quantité de travail peut être intégrée sans casser le système, alors il l’intègre …
En intégrant au minimum quotidiennement
À quelle fréquence est-ce “continue” ? Aussi fréquemment que possible ! Ceci est limité par
- la capacité à fractionner de gros changements
- la vitesse d’intégration
- la vitesse du cycle des retours d’informations
Capacité à fractionner des gros changements - fractionner des gros changements en petits changements, tout en conservant dans un état opérationnel les anciennes fonctionnalités, est une compétence qui doit être apprise. Les meilleurs développeurs sont ceux qui, dans cette perspective du fractionnement, intègrent le plus fréquemment. Le développement piloté par les tests, en cycles courts de 10 minutes, est une très bonne technique pour arriver à cela.
Vitesse d’intégration - plus l’intégration des changements prendra du temps dans le dépôt de code, moins les développeurs le feront fréquemment. Les changements sont lotis dans un souci d’efficacité.
L’effort d’intégration est impacté par le surcoût du processus (le coût de transaction), tel que les approbations et les revues nécessaires avant que les développeurs soient autorisés à intégrer. Il faut réduire ce surcoût ou trouver des manières créatives de faire les choses différemment. Par exemple, nous avons travaillé avec un groupe produit de 40 personnes dans lequel le message de réservation (check-in en anglais dans le texte pour les lecteurs plus habitués avec ce terme - NdT) devait mentionner la personne qui avait revu le code. Le résultat ?
Les développeurs ont loti beaucoup de changements pour rendre les revues de code plus “efficaces” et cela a eu comme conséquence de retarder l’intégration - une optimisation locale. La solution ? Les revues de code peuvent être faites à la place sur du code intégré - ce qui a pour effet de ne pas retarder l’intégration.
Vitesse des cycles de retours d’informations - un développeur ne devrait intégrer que les changements qui ne cassent pas les tests existants. Idéalement, il fait tourner tous les tests avant l’intégration. Pour que cela soit possible, les tests doivent être exécutés très vite. Si les tests sont lents, le développeur retardera l’intégration pour “travailler plus efficacement”.
Toutefois, exécuter tous les tests rapidement c’est difficile sur de gros systèmes. Par conséquent, les développeurs exécuteront uniquement un sous-ensemble des tests avant d’enregistrer et un système d’intégration continue exécutera les tests restants. Le système d’intégration continue agira comme un filet de sécurité en donnant au développeur des retours d’informations sur les tests qu’il n’a pas lui-même exécuté. Que se passe t’il quand le système d’intégration est lent ? Premièrement, il y aura beaucoup de changements pendant le premier cycle, augmentant la probabilité que le compilation casse. Deuxièmement, les développeurs n’intègrent pas leurs changements dans une compilation qui est cassée ; à la place, ils les lotissent. À la fin, quand la compilation est corrigée, tous les développeurs intègrent leurs changements lotis, cela ayant pour conséquence d’augmenter encore les probabilités de casser à nouveau la compilation. Par conséquent, le cycle filet de sécurité-retours d’informations se doit d’être rapide. Cela diminue la probabilité de casser la compilation et augmente la capacité d’enregistrer (check-in) plus fréquemment.
Une règle empirique pour les gros produits qui veulent aller vers du développement agile et lean : tous les développeurs doivent intégrer au moins une fois par jour. Même si “les compilations quotidiennes sont pour les mauviettes” Jeffries04, le faire quotidiennement est une première étape pour les gros produits.
Il faut se rappeler de la métaphore “du lac et des rochers” utilisée dans la pensée lean - le gros rocher qui consiste à être juste capable de compiler une fois par jour avec les mises à jour de tout le monde est déjà assez difficile à traiter sur les gros vieux systèmes avec 300 développeurs répartis dans quatre pays. Un jour ou l’autre, le gros rocher sera enlevé, et de plus petits cycles seront possibles.
Sur de gros produits, cela prendra du temps d’apprendre à fractionner les changements, de simplifier le processus d’intégration, et de mettre en place un système d’intégration continue rapide et opérationnel …
Sur la ligne de version principale
Les développeurs intègrent sur la ligne de version principale ou tronc BA03. Effectuer des changements sur une branche séparée signifie que l’intégration sur la branche principale est retardée4. L’état actuel (des développements - NdT) n’est pas visible, donc vous ne pouvez pas savoir pas si tout fonctionne ensemble.
Développer en utilisant des branches différentes brise l’objectif de l’intégration continue et devrait être évité. Il existe des exceptions : tout d’abord, les clients pourraient ne pas vouloir mettre à jour leur produit avec la dernière version mais voudraient continuer à bénéficier de rustines (patches - NdT). Donc, des branches de versions sont nécessaires5. Ensuite, lors de la montée en puissance d’un système d’intégration continue, il peut être utile d’avoir des branches ayant une durée de vie très courte qui sont intégrées automatiquement dans la ligne principale - nous aborderons ce dernier point plus tard.
Qu’en est-il des branches pour gérer la personnalisation ? Très mauvaise idée ! À la place, il faut gérer plutôt cela à travers une conception configurable ou une compilation paramétrée au lieu d’utiliser le système de gestion de configuration logicielle (GCL). Nous avons eu l’occasion de travailler sur un produit d’optimisation réseau fait par un groupe produit, ce dernier a insisté pour travailler avec des branches pour gérer différentes configurations. Les développeurs ont travaillé sur ces différentes branches pendant un an. Après ça, il leurs a fallu un semestre supplémentaire - et énormément luttés - pour les fusionner avec le tronc.
Un développement réussi d’une ligne principale est …
Supporté par un système d’intégration continue
Le Lean insiste sur la minimisation des stocks - qui est l’un des types de gaspillage connus. Le stock agit comme un tampon (un autre type de files d’attente) dans lequel les erreurs se cachent. Les erreurs deviennent douloureusement visibles lorsque ces tampons sont supprimés - et il s’agit là d’une bonne chose. La même chose se produit lorsque tous les changements sont intégrés directement dans la ligne principale. Tous les développeurs mettent à jour leur copie locale fréquemment ; lorsque quelqu’un y enregistre un code foireux, il devient visible aux yeux de tout le monde - tous les développeurs seront alors ennuyés.
Les gens font des erreurs. C’est normal. Un filet de sécurité lean du type arrêtez-les-machines est nécessaire pour les détecter au plus tôt.
Les développeurs corrigent une anomalie avant qu’elles n’affectent les autres. Ce filet de sécurité, un système de type andon, dans la terminologie Toyota, est un système d’intégration continue.
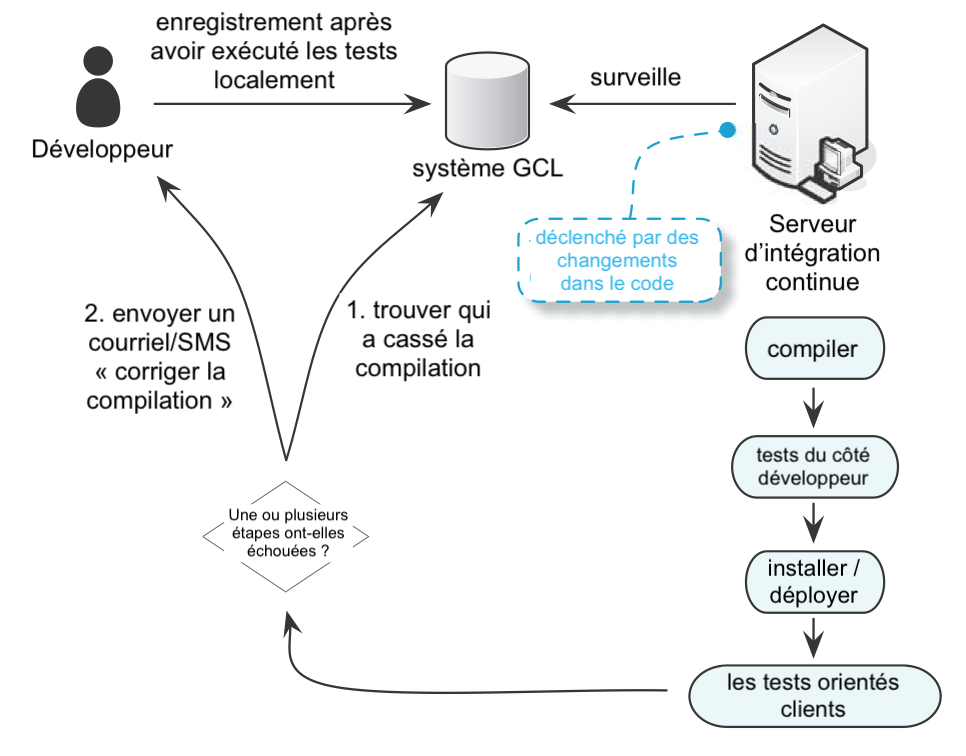
Un système d’intégration continue (Voir système d’intégration continue) est à l’écoute d’un système de gestion de configuration logicielle.
Lorsqu’un développeur y enregistre son code, le système d’intégration continue prend tout le code, le compile, exécute quelques tests, l’installe, et exécute quelques tests supplémentaires. Tout cela se déroule vite ; l’Extreme Programming recommande que cela se déroule en moins de dix minutes. Si un développeur casse la compilation, le système d’intégration continue fera une requête au système de gestion de configuration logicielle et trouvera qui a fait le changement. Il lui enverra un courriel disant : “Tu as cassé la compilation, répare-la !”.
Corriger la compilation cassée devient la priorité numéro une parce que cela impacte tout le monde.
Pour un petit produit, il est facile de faire une compilation rapide, en moins de dix minutes. Pour un gros produit avec du code existant et beaucoup de développeurs, c’est un défi. Nous verrons dans un prochain chapitre différentes techniques permettant de faire monter en puissance un système d’intégration continue…
Avec beaucoup de tests automatisés
Ce n’est pas très difficile d’avoir un système d’intégration continue qui puisse tout compiler ; ce n’est pas très utile non plus. Ce que vous voulez c’est avoir le plus de tests possibles s’exécutant dans votre système d’intégration continue. Plus il y a de tests automatisés, meilleur est votre filet de sécurité et plus vous aurez confiance dans un système opérationnel.
Pour les nouveaux produits, créer des tests automatisés n’est pas difficile. Toutefois, beaucoup de gros produits ont du code existant sans tests automatisés. Les développeurs doivent alors ajouter des tests automatisés - ce qui représente beaucoup de travail. Le chapitre traitant du code existant évoque ce sujet.
Étendre un système d’intégration continue
Tout d’abord, la compilation et les tests doivent être entièrement automatisés. Beaucoup de groupes produits de taille importante avec lesquels nous avons travaillé ont des étapes manuelles à faire lors de la compilation. Jetez donc un œil sur les ouvrages recommandés en bas de page pour prendre connaissance des textes utiles évoquant le sujet de l’automatisation de la compilation.
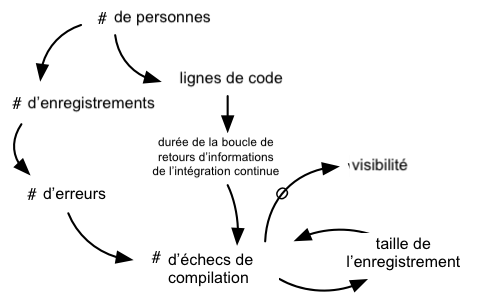
Les obstacles pour étendre un système d’intégration continue sont liés à l’augmentation du nombre de personnes, de la quantité de code et de tests produits. Premièrement, la probabilité de casser la compilation s’accroît avec le nombre de personnes enregistrant du code. Deuxièmement, une augmentation de la taille du code conduit à un ralentissement de la compilation et de la boucle de retours d’informations du système d’intégration continue. Ces différents éléments peuvent mener à un échec en continu de la compilation (Voir les dynamiques des compilations cassées).
Les solutions sont simples :
- accélérer la compilation
- implémenter un système d’intégration continue multi-étapes
Travail numéro un : Accélérer la compilation. Si l’ensemble du produit peut être compilé et testé en une seconde, les techniques pour étendre le système d’intégration continue à grande échelle s’avèrent alors inutiles. La compilation en une seconde est hors de portée des gros produits, pour l’instant. Même si chaque amélioration nous en rapproche petit à petit, la compilation d’une seconde s’avère bien utile. Donner des règles générales pour accélérer les compilation est difficile - c’est une question qui souvent liée au produit en tant que tel. Voici quelques solutions d’ordre général Rasmusson04 :
- ajouter du matériel
- paralléliser
- changer les outils
- construire incrémentalement
- déployer incrémentalement
- gérer les dépendances
- refactorer les tests
Ajouter du matériel - la manière la plus facile d’accélérer la compilation est d’acheter davantage de matériel. Ajouter deux ou trois ordinateurs de plus, davantage de mémoire, ou une connexion réseau plus rapide, devrait permettre de résoudre le problème.
Mettre à jour le matériel existant demande un investissement en argent et un minimum d’effort, ce qui en fait le meilleur choix et le plus facile. Un produit télécom a pu être compilé avec un gain en terme de vitesse de 50% sur un disque RAM - et cela avec une simple augmentation mémoire.
Paralléliser - en relation avec l’ajout de matériel, se trouve la parallélisation et la compilation distribuée. Cela nécessite souvent de revoir la conception les scripts de compilation, de changer les outils, ou même de construire de nouveaux outils. Par conséquent, cela demande plus d’effort qu’ajouter simplement du nouveau matériel. Un gros produit télécom a obtenu un gain de son temps de compilation en distribuant la compilation de chaque composant sur du matériel dédié.
Changer les outils - mettre à jour les outils dans leur dernière version ou remplacer un outil lent par un outil rapide permet d’accélérer grandement la compilation. Il nous est arrivé, en changeant simplement de compilateur, de diminuer le temps de compilation de 50%.
Une problématique assez répandue que nous avons pu constater est l’utilisation d’un outil lent, IBM Rational ClearCase pour ne pas le nommer. À chaque fois qu’un groupe produit a changé de ClearCase pour Subversion - très bon système open-source de gestion de configuration logicielle (ou GCL) - ce groupe a … premièrement accéléré la compilation (nos clients ont eu un gain de 25 à 50%) ; deuxièmement, permis d’économiser une somme substantielle avec le coût des licences ; et troisièmement, amélioré la vie des développeurs, notamment dans les groupes avec lesquels nous avons travaillé et pour qui ClearCase était l’outil de développement qu’ils détestaient le plus. Certaines personnes mal informées ont argumenté en disant que Subversion n’est pas adapté pour le développement de gros produits. Mais nous l’avons vu en action dans des groupes produits de 400 personnes répartis à travers le monde.
De manière plutôt ironique, les soi-disantes fonctionnalités à grande échelle de ClearCase telles que le support multi-sites, ont rendu l’intégration continue impossible car elles forçaient les utilisateurs à avoir une appropriation individuelle du code.
Construire incrémentalement - vous devez compiler uniquement les composants ayant changé et exécuter les tests associés. Facile en théorie ; difficile en pratique. Les dépendances entre les composants, les changements dans les interfaces ou les binaires incompatibles sont quelques-unes des choses qui font que compiler uniquement ce qui a changé est une proposition qui s’avère difficile. Pour les mêmes raisons, trouver tous les tests associés aux composants ayant changé peut être difficile. Les compilations incrémentales sont rarement fiables à 100%, et pour empêcher la corruption de la compilation incrémentale, c’est une bonne idée de continuer à avoir une compilation quotidienne correcte.
Déploiement continu - sur de gros produits embarqués, cela prend énormément de temps de déployer ou d’installer un logiciel ; un produit télécom de radio communication sur lequel nous avons travaillé a mis plus d’une heure à se déployer. Ce n’est pas quelque chose d’inhabituel.
Les tests vont plus vite lorsque le déploiement est fait de manière incrémentale - car seuls les composants ayant changé sont déployés. Les changements doivent être chargés, ce qui peut être fait en redémarrant le système. Toutefois, démarrer un gros système prend du temps, par conséquent certains systèmes sont mis à jour dynamiquement - une fonctionnalité importante dans les télécoms et dans les autres industries où le temps d’indisponibilité s’avère très cher. Le déploiement incrémental - et tout spécialement la mise à jour dynamique - demande des changements dans le système, mais cela rend cette option difficile.
Gérer les dépendances - une cause assez répandue de la lenteur des compilations est la non gestion des dépendances. Exemples : les fichiers d’en-tête peuvent inclure plusieurs autres fichiers d’en-tête, ou bien plusieurs cycles de liens peuvent être nécessaires pour résoudre les dépendances de liens cycliques (type de lien récursifs - NdT). Pour un produit multimédia, nous avons passé plusieurs heures à ré-ordonner les dépendances des liens - divisant ainsi le temps de moitié. Réduire les dépendances permet d’accélérer la compilation et par effet de bord d’améliorer la structure de votre produit.
Notez bien ce point clé
Améliorer la compilation permet d’améliorer la structure de votre produit. Pourquoi ? Parce qu’une mauvaise structure devient cruellement visible lorsque vous essayez de réduire le temps de cycle de la compilation.
Il s’agit d’un point lean dont nous avons discuté précédemment : un effet de bord très puissant d’un temps de cycle réduit c’est la nécessité d’améliorer radicalement les processus et le produit pour pouvoir supporter des temps cycles courts et des lots de petites tailles.
Refactorer les tests - malheureusement, beaucoup de développeurs se soucient moins du code de test que du code de production. Le résultat ? Du code de test mal structuré et des tests lents. Une fois, il nous est arrivé de passer une demi-journée à refactorer les tests - et accélérer la compilation de 60% ! En profilant et refactorant les tests, vous pouvez fréquemment faire ce genre de petites victoires.
Un système d’intégration continue en plusieurs étapes fractionne la compilation et l’exécute dans des cycles de retours d’informations différents. Au niveau le plus bas, il s’agit d’une intégration continue très rapide avec les tests unitaires et quelques tests fonctionnels.
Lorsque cette intégration continue réussie, elle déclenche une
compilation de plus haut niveau contenant les tests systèmes les plus lents. Plus le produit est gros plus il y a d’étapes.
Un système d’intégration continue est comparable à la culture “arrêt de la ligne de production” de Toyota. Lorsqu’une anomalie est détectée, Toyota arrête la ligne de production, et la première priorité est de corriger l’anomalie et sa cause racine. Est-ce qu’un système d’intégration continue en plusieurs étapes est en contradiction avec ce principe lean ? Non. Une attitude arrêt-de-la-ligne-de-production est absolument nécessaire, mais cela ne signifie pas que vous devriez arrêter aveuglément tous les travaux. Même Toyota ne fait pas ça LM06a.
Toyota a développé un système qui permet aux problèmes d’être identifiés et remontés sans qu’il soit nécessaire d’arrêter la ligne de production. Lorsqu’un problème est identifié et que la corde est tirée, l’alarme résonne et une lumière jaune s’allume. La ligne de production continue jusqu’à la fin de la zone de travail - le point de la “position fixe stop” … la ligne de production s’arrêtera lorsque la position fixe sera atteinte et que l’andon deviendra rouge.
Un système d’intégration continue à plusieurs étapes fonctionne de la même manière. Vous identifiez le problème au plus tôt et travaillez à sa résolution, mais vous ne voulez pas qu’il affecte tout le monde. Et c’est seulement si le problème s’avère vraiment sérieux que vous allez “arrêter la ligne de production”.
Lorsque vous mettez en place un système d’intégration continue, réfléchissez bien
- à ce qui est fait par un développeur
- à mettre l’accent sur un composant ou une fonctionnalité
- à choisir entre promotion automatique ou manuelle
- à choisir entre déclenchement évènementiel ou temporel
- au nombre d’étapes
À ce qui est fait par un développeur - les développeurs pratiquant l’intégration continue doivent vérifier leurs changements avant d’enregistrer. Par conséquent, ils doivent être capables de travailler avec un sous-ensemble du système, souvent un composant, et être capables d’exécuter des tests unitaires dessus. Prenez bien cela en considération lorsque vous automatisez votre compilation.
À mettre l’accent sur le composant ou la fonctionnalité - un système traditionnel d’intégration continue à plusieurs étapes est structuré autour des composants. Les compilations de bas niveau compilent un composant, le niveau suivant un sous-système, et le plus haut niveau compile l’ensemble du produit. Avec des équipes organisées autour des composants, l’équipe est donc aux petits soins pour son système d’intégration continue [AKB04 (lien mort : http://www.cmcrossroads.com/articles/agilemar04.pdf)]; Mais où mettre les tests d’acceptation de haut niveau, et qu’en est-il des équipes feature ? Une alternative est de structurer votre système d’intégration continue autour des fonctionnalités. Lorsque quelqu’un enregistre son code, tous les systèmes d’intégration continue associés aux fonctionnalités se déclencheraient. Les tests sont maintenant exécutés en parallèle, mais le même composant est compilé plusieurs fois.
Un groupe produit distribué, avec lequel nous avons travaillé, mélange les deux approches. À bas niveau, le système d’intégration continue est organisé autour des composants, et le résultat déclenche les systèmes d’intégration continue des différentes fonctionnalités qui exécutent les tests d’acceptation de haut niveau en parallèle.
À choisir entre promotion automatique ou manuelle - laisser le système d’intégration continue à l’écoute de la ligne principale à chaque étape créé de la pagaille. Lorsqu’un développeur fait une erreur, toutes les étapes plantent les unes après les autres. Un système d’intégration continue de haut niveau se déclenche à l’annonce qu’un composant peut être utilisé. Ce type d’annonce s’appelle une promotion et s’effectue en étiquetant (ou en marquant) le composant.
Promouvoir un composant peut se faire de manière automatique ou manuelle Poole08. Avec une promotion automatique le système d’intégration continue bas niveau promeut un composant juste après l’arrivée de celui-ci. De manière générale, évitez la promotion manuelle où l’équipe décide quand le composant est “assez bon”.
À choisir entre déclenchement évènementiel ou temporel - chaque système d’intégration continue est déclenché soit par un événement soit à un moment précis. Les systèmes d’intégration continue bas niveau sont toujours déclenchés par un événement - l’enregistrement du code. Pour les systèmes d’intégration continue de haut niveau, le déclencheur est soit la promotion d’un composant soit à un moment donné précis. Le déclenchement par promotion est plus rapide, mais pour des compilations qui prennent du temps, cela ne vaut pas le coup de faire des efforts supplémentaires dans des actions de configuration et de maintenance. Une compilation haut niveau quotidienne pourrait s’avérer suffisante Vodde08.
Par exemple, un groupe produit distribué avec lequel nous avons collaboré, travaille avec des systèmes d’intégration continue bas niveau déclenché par code, un système d’intégration continue plus haut niveau déclenché par promotion, et une compilation quotidienne exécutant les tests qui durent huit heures.
Au nombre d’étapes - la taille du produit et la présence de code déjà existant déterminent le nombre de niveaux nécessaires pour les systèmes d’intégration continue. Les étapes habituelles sont :
- l’échelon composant rapide* - correspond à un système d’intégration continue bas niveau très rapide pour avoir des retours d’informations rapides. Il exécute les tests unitaires, la couverture de code, l’analyse statique et les indicateurs de complexité
- l’échelon composant lent* - correspond à un système d’intégration continue bas niveau et assez lent. Il exécute les tests d’intégration et les tests au niveau composant qui sont lents.
- l’échelon stabilité produit* - correspond à un système d’intégration continue très rapide au niveau produit pour avoir des retours d’informations rapides sur la stabilité du produit. Il exécute des tests fonctionnels rapides (tests de recevabilité)
- l’échelon feature* - correspond à un système d’intégration continue lent et haut niveau. Il exécute les tests fonctionnels et d’acceptations.
- l’échelon système* - correspond à un système d’intégration continue lent et haut niveau. Il exécute les tests au niveau système qui durent souvent des heures.
- l’échelon stabilité et performance* - correspond à un système d’intégration continue très lent et haut niveau. Il exécute des tests de stabilité et de performance de manière continue, ce qui prend généralement plusieurs jours si ce n’est plusieurs semaines.
Jusqu’à présent, nous n’avons pas encore vu l’ensemble des étapes mis en place pour un seul et même produit. La plupart des produits sélectionnent les étapes qui leurs semblent les plus importantes et ajoutent des étapes supplémentaires lorsque c’est nécessaire. Un système d’intégration continue inutilement complexe est du gaspillage.
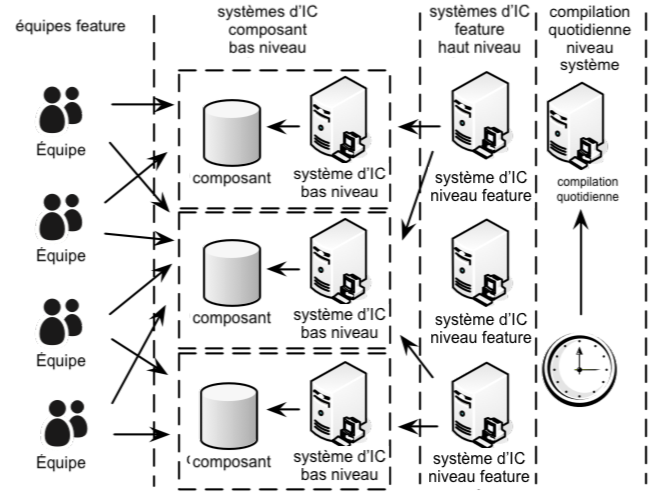
Exemple de système d’intégration continue
Le diagramme ci-dessous vous donne un exemple de système d’intégration continue comportant plusieurs étapes. Dans cet exemple, chaque composant a un système d’intégration continue exécutant des tests unitaires, de l’analyse statique ainsi que des indicateurs de couverture de code. Une compilation réussie promeut alors le composant et déclenche ensuite les systèmes d’intégration continue au niveau feature qui eux-mêmes exécutent des tests de plus haut niveau. Une compilation quotidienne exécute les tests systèmes comme par exemple des tests de performance.
Un système d’intégration continue peut effectivement inclure du management visuel - qui est l’un des principes lean. Lorsque la compilation plante, un signal visuel indique son échec - autrement dit un système andon (dans la terminologie Toyota). Ce signal n’est pas à l’attention des manageurs pour qu’ils punissent le développeur responsable de l’échec de la compilation ; il est pour les développeurs afin de voir l’état de la compilation. Que vont-ils faire de cette information ? Enquêter sur ce qui se passe ou sur ce qui retarde l’intégration à l’échec de la compilation. Si plus tard, le signal visuel indique que l’échec est toujours présent, des personnes supplémentaires pourront chercher pourquoi cela n’a pas été corrigé.
La lampe à lave est un outil visuel branché aux systèmes d’intégration continue qui est devenu populaire dès l’apparition de premiers systèmes d’intégration continue. Une lampe à lave qui fait des bulles vertes indique une compilation réussie. Et des bulles rouges en cas d’échec.
Après les lampes à lave, les gens ont commencé à brancher toutes sortes d’éléments pour visualiser le résultat de la compilation, comme des guirlandes lumineuses de Nöel, des sirènes, des squelettes animés qui crient lorsque la compilation est cassée. Même si cela est moins amusant, un simple moniteur avec une page web présentant un gros cercle de couleur rouge ou vert (un écran rouge-vert) est plus facilement reproductible. Les écrans rouge-vert sont en train de devenir la norme dans les systèmes d’intégration continue à grande échelle. Certaines versions incluent un signal jaune pour indiquer que “la compilation qui était plantée a été corrigée”. Un gros cercle de couleur tout simple - visible de loin - est un élément clé, mais l’affichage peut être enrichi de textes ou de diagrammes chiffrés, tel que la durée de compilation ou le taux de couverture de test. L’information n’a pas à se limiter aux informations de compilation [Rogers08].


Voici un petit message d’avertissement de Jeffrey Liker à propos du management visuel LH08:
Ce n’est pas parce qu’il y a représentation visuelle qu’il s’agit de management visuel. Il est relativement facile de mettre en place de belles zones d’affichage qui seront là pour faire jolies. Le véritable défi est de les rendre “utilisables”. Parmi les gens qui visitent le site de Toyota, un certain nombre d’entre eux évoquent la différence entre leur approche et celle de Toyota. Nous entendons régulièrement des commentaires comme “Maintenant je vois, ce qui est affiché par Toyota permet vraiment d’orienter les actions au quotidien”. C’est là en effet toute la différence, et Toyota suggèrerait que si cela ne sert pas à orienter les actions au quotidien alors autant s’en débarrasser.
Sur les produits de taille importante, il s’avère encore plus difficile de fractionner de gros changements. Les développeurs veulent quelques fois restructurer ou ré-architecturer leur système existant et sont convaincus que cela doit être fait en un seul gros changement. Mais nous n’avons pas encore vu de gros refactoring qui ne pourraient être fait graduellement. À chaque fois, après discussion avec les développeurs, nous avons trouvé des moyens de fractionner ce gros refactoring qui-ne-pouvait-pas-l-être. RL06.
Les changements d’interface sont un problème assez répandus dans les gros systèmes. Beaucoup de composants utilisent des interfaces et doivent être modifiés en conséquence - ce qui rend impossible de le faire graduellement, c’est bien ça ? Pas tant que ça. En fait, un changement d’interface dans une API (interface de programmation applicative - NdT), est assez répandue et pour laquelle il existe une solution bien connue :
Chaque étape peut être faite indépendamment et à différents moments. Pour les APIs publiques, il est impossible de savoir s’il y a encore des utilisateurs pour l’ancienne interface. Il s’avère donc difficile de supprimer l’ancienne interface. Mais la plupart des interfaces concernées ne font pas partie de l’API publique, donc n’oubliez pas de supprimer celles qui sont obsolètes. Nous avons vu plusieurs produits se retrouver avec trois voire quatre interfaces systèmes ou interfaces de journalisation parce que les anciennes n’avaient jamais été supprimées.
À faire et à ne pas faire
La section précédente faisait allusion aux choses qui sont à faire ou à ne pas faire concernant l’intégration continue :
À FAIRE - enregistrez et intégrez à chaque cycle de TDD (par exemple toutes les 5 ou 10 minutes) - Et en tant que développeurs nous-mêmes ayant les mains dans le cambouis nous savons qu’il est facile d’être plus rapide avec du nouveau code, mais que cela s’avère plus difficile avec du vieux code bordélique.
À NE PAS FAIRE - Ne développez pas sur des branches dédiées - Si vous utilisez un outil distribué tel que Git, poussez vers le ‘master’ (le nom donné dans Git au tronc commun ou à la ligne principale) commun à chaque cycle de TDD.
À NE PAS FAIRE - N’ayez pas une politique de revue de code avant d’enregistrer - Si vous faites cela, vous allez retarder l’intégration, engendrer d’autres problèmes de qualité importants et un certain nombre d’autres difficultés qui resteront cachées ! À la place …
À FAIRE - Associez qualité et code pour favoriser une intégration optimiste - Comment passer d’une politique pessimiste d’intégrations différées suite à revues de code à une politique optimiste d’intégrations au plus tôt ? Mettez en place une culture autour de l’artisanat logicielle (consultez le manifeste du Software Craftsmanship pour en savoir plus - NdT), du développement piloté par les tests et du refactoring pour du code propre, autour de la programmation en binôme ou en groupe pour faire-de-la-revue-tout-en-codant, et autour des outils de vérification de code automatisée. Et si les revues de code sont toujours souhaitées, faites-les sur un cycle davantage espacé sur des petits lots de code déjà enregistrés.
À NE PAS FAIRE - N’ayez pas une politique du type “Interdiction de planter la compilation” ; et ne faites PAS de reproches et ne blâmez PAS qui que ce soit en cas de plantage de la compilation - si vous faites ce genre de choses, cela engendrera de la peur et les gens vont éviter de faire de l’intégration. Alors une fois de plus, une intégration longtemps différée engendrera de nombreux problèmes qui resteront cachés.
À la place…
À FAIRE - Rendez facile le fait d’échouer rapidement, de stopper et de corriger, et d’apprendre des ‘erreurs’ - créez un système d’intégration continue aussi rapide que l’éclair qui donne de rapides retours d’informations en cas d’échec de la compilation.
Éliminez les barrières qui empêchent les gens de pratiquer le “stopper et corriger”.
Créez un environnement offrant une sécurité personnelle où les gens peuvent admettre les problèmes et apprendre à s’améliorer.
À FAIRE - “stoppez et corrigez” en cas d’échec de la compilation - “Nous sommes trop occupés à gérer les problèmes pour corriger la compilation qui s’est plantée.” Devons-nous vous le répéter en articulant mot par mot ? Ne réfléchissez pas de cette manière.
À FAIRE - Utilisez du management visuel pour montrer l’état de la compilation - Utilisez de vieux ordinateurs ou des ordinateurs dont personne ne veut et suivez ‘tout ce qu’il se passe’ montrant où en est l’état de la compilation.
Utilisation de l’activation des fonctionnalités
Comme pour l’intégration continue, l’activation des fonctionnalités est trop souvent (malheureusement) perçue comme n’étant pas un mécanisme favorisant la coordination et l’intégration.
Un problème fréquent d’intégration-coordination des grands groupes est que certaines équipes ont ajouté des fonctionnalités qui sont immédiatement prêtes à être utilisées, alors que d’autres équipes ont ajouté des fonctionnalités qui ne sont pas prêtes pour tout de suite et qui ne devraient pas être rendues visibles. Cela se produit généralement lorsque les fonctionnalités ne sont pas suffisamment étoffées pour être utile à minima. Plutôt que retarder l’intégration en travaillant sur des branches séparées ou de ne pas enregistrer le code, que faire ?
L’activation de fonctionnalité permet de montrer ou pas des fonctionnalités en configurant certains paramètres, tout en continuant d’intégrer de manière continue l’ensemble du travail fait par les développeurs et les équipes. Et pour le faire à grande échelle, vous pouvez utiliser des outils open-source comme Togglz.
L’activation de fonctionnalité peut se faire en insérant très simplement un élément conditionnel au niveau du code. Donc pourquoi utiliser un outil dédié ? Ce qui rend des outils comme Togglz utiles dans un contexte de grande échelle ce sont les possibilités d’administrations pour la gestion des activations des fonctionnalités sur différents déploiements, comme par exemple un déploiement en production versus un déploiement en bac à sable.
Conclusion
Par où commencer ? Faire de l’intégration continue exige de :
- changer le comportement des développeurs
- mettre en place un système d’intégration continue
Changer le comportement des développeurs - Faire des produits de taille importante veut dire avoir beaucoup de monde, il s’agit donc effectivement d’une tâche difficile. Focalisez-vous sur le TDD - qui est une très bonne technique pour fractionner un gros changement en plus petits. Faites appel à des coachs TDD, qui feront de la programmation en binôme avec vos développeurs, qui est une manière très efficace pour apprendre le développement piloté par les tests. Mais soyez patient. Le développement piloté par les tests est un changement qui s’avère difficile pour la plupart des développeurs et son apprentissage prend du temps.
Mettre en place un système d’intégration continue - La plupart des produits sur lesquels nous avons travaillé ont lancé un projet dédié pour mettre en place un système d’intégration continue. Cela fonctionne, même si une meilleure alternative consisterait à l’ajouter au Backlog Produit et à laisser une équipe feature travailler dessus. Cela permet d’obtenir davantage de visibilité ainsi qu’un sentiment d’appropriation - les développeurs sont aussi des utilisateurs.
La plupart des problèmes d’implémentation de l’intégration continue sont d’ordre organisationnels et non techniques. Sur un certain nombre de produits sur lesquels nous avons pu travailler, nous avons vu l’intégration continue devenir un véritable désordre organisationnel. On y retrouve tout un ensemble de fonctions traditionnelles mélangées avec de nouveaux rôles : des développeurs, des responsables, des testeurs, des ingénieurs en automatisation de tests, des Scrum Masters, des coachs agiles, des administrateurs de GCL et le département des technologies de l’information. Et qu’est-ce que cela donne ? Des responsabilités floues, des personnes s’accusant les unes les autres et des comités (également connue sous le nom de “groupes de pilotage”) discutant sans fin en l’absence des personnes qui font vraiment le boulot. Et le résultat alors ? Ça n’avance pas. Si cela vous arrive, n’essayez pas de cacher les problèmes organisationnels avec des solutions techniques et n’abandonnez pas sous le motif que “notre produit est trop complexe pour faire de l’intégration continue”.
Pourquoi ne pas avoir abandonné alors ? Parce que chaque groupe produit avec lequel nous avons travaillé est passé par là, par ce processus “d’enlever ce gros caillou de la chaussure” pour réussir à faire de l’intégration continue et tout le monde a en fin de compte trouvé cela infiniment utile.
Lectures recommandées
Quelques lectures au sujet de l’intégration continue
- Extreme Programming Explained, par Kent Beck.. Le terme intégration continue a été pour la première fois utilisé dans la méthode Extreme Programming.
- Continuous Integration, par Martin Fowler. - il s’agit probablement de la meilleure description d’intégration continue disponible actuellement.
Quelques autres lectures recommandées au sujet de l’automatisation des compilations :
- Managing Projects with GNU Make, par Robert Mecklenburg.. Si vous travaillez avec du C/C++, vous aurez de grandes chances d’utilisez Make. Cet ouvrage donne une très bonne vision global de Make et aborde également l’usage de Make dans le développement à grande échelle..
- Ant in Action , par Steve Loughran and Erik Hatcher.. Si vous travaillez avec Java, vous aurez de grandes chances d’utiliser Ant. Ce livre aborde avant tout Ant, mais également d’autres sujets et outils comme Maven - qui est un autre outil très répandu dans le domaine de l’automatisation de la compilation.
- Groovy in Action, par Dierk Koenig, Andrew Glover, Paul King, Guillaume Laforge, Jon Skreet.. Groovy est un langage de programmation assez récent basée sur la JVM. Il offre un très bon support de l’automatisation de la compilation.
- Pragmatic Project Automation: How to Build, Deploy and Monitor Java Apps, par Mike Clark.. Un petit livre abordant différentes technologies liées à l’automatisation des compilations sur Java.
- Continuous Integration: Improving Software Quality and Reducing Risk, par Paul Duvall, Steve Matyas, and Andrew Glover.. L’objet de ce livre est davantage sur l’automatisation de la compilation que sur la pratique de l’intégration continue.
L’intégration continue dans les développements à grande échelle :
- “Scaling Continuous Integration ,” par Owen Rogers (aussi présent sur: exortech.com/blog/wp-content/uploads/2008/05/scaling-ci-3.pdf) dans Extreme Programming and Agile Processes in Software Engineering 2004 Conference Proceedings.
Auteur : The LeSS Company B.V.
Source : Continuous Integration - Large Scale Scrum (LeSS)
Traducteur : Nicolas Mereaux
Relecture : Fabrice Aimetti
Date : 20/11/2018

Ce(tte) oeuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
-
Tiré d’un article dénommé Continuous Integration and Automated Builds at Enterprise Scale qui auparavant était disponible sur blog.aspiring-technology.com/file.axd?file=Continuous+Integration+at+Enterprise+Scale.pdf. Malheureusement ce lien est mort. Si quelqu’un connaît un nouveau lien pour ce document, dites-le nous. ↩
-
CruiseControl.NET est un serveur d’intégration continue pour Microsoft .NET. ↩
-
Pour Java, dix minutes c’est trop long. En C++, c’est la moyenne. En C, c’est sans doute trop court. Dix minutes est un temps moyen pour un cycle de TDD quel que soit le langage utilisé. ↩
-
Pour être plus précis, évitez les branches ayant une durée de vie de plus de quelques heures. L’utilisation des branches est devenue plus facile avec les systèmes distribués de contrôle de version comme Git et Mercurial. Avoir une utilisation mesurée de branches ayant des durées de vie brèves peut s’avérer utile … mais c’est une arme à double tranchant qui peut facilement être mal utilisée Fowler09. ↩
-
Astuce : créez donc une branche de livraison en dehors de ligne principale juste avant la livraison, non au démarrage de la livraison (une ligne de livraison). ↩