Questions/Réponses à propos de la vélocité 3ème partie
Dans la 2ème article de cette série, nous avons parlé de la vélocité et de cette ligne (implicite) qui est de faciliter les choses pour le travail à faire plutôt que mettre encore plus de pression. Notre personnage « A » se posait la question si les unités utilisées lors des estimations pourraient être d’une aide quelconque et qui, bien sûr, ne le sont pas.
Nous reprenons à partir de ce moment-là cette semaine avec ce petit extrait d’une discussion qui abordent quelques idées importantes :
A : Alors comment est-ce que je peux faire pour obtenir mes 30 points de vélocité ?
B : Et s’il n’y avait aucune manière d’y arriver ? Peut-être devriez-vous être moins exigeant ?
A : Mais et le planning … !
B : Le planning c’est quelque chose d’abstrait, de construit de toute pièces. La durée que cela prend de faire les choses c’est ça la réalité.
Les estimations en informatique s’avèrent souvent fausses.
Assez souvent, elles s’avèrent inexactes d’environ 200 % sur des items bien précis. Il y a une très bonne raison pour cela : les éléments fournis ne sont ni uniformes ni standardisés et le processus n’est pas standardisé non plus. Nous non plus. Si la fonctionnalité souhaitée par le client a déjà été écrite, nous n’allons pas l’écrire à nouveau.
Les développeurs n’aiment pas se répéter. Chaque problème et chaque solution est (un tant soit peu) unique.
Par conséquence, chaque estimation comporte non seulement l’effort à fournir mais aussi le risque (de casser quelque chose) et l’incertitude (le besoin d’apprendre quelque chose).
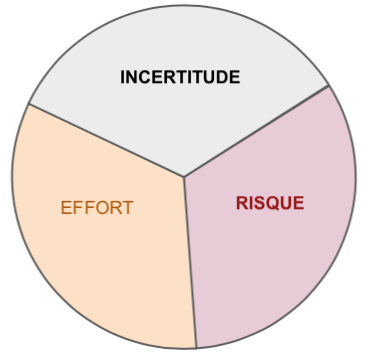
- Comment de bien cela va vous prendre pour apprendre comment faire quelque chose que vous n’avez jamais fait ?
- Quelles sont les chances pour qu’en ajoutant cette nouvelle fonctionnalité que cela impactera négativement la performance de l’application, siphonnera la mémoire ou compliquera le déploiement ?
- Quelle est la probabilité de voir arriver d’autres conséquences inattendues ou accidentelles, qui seront dues, peut-être, à des options différentes de configuration.
- Pouvons-nous facilement comprendre le code que nous allons devoir modifier, ou est-ce que va nous demander des efforts considérables pour déchiffrer l’intention originelle et appréhender tous les effets de bord.
Le facteur risque grimpe de plus en plus au fur et à mesure que le système grandit. Toutes les fonctionnalités supplémentaires et notamment les fonctionnalités ‘implémentées au chausse-pieds’ (avec des bidouillages vite faits mal faits “pour que ce soit fait rapidement”) vont augmenter les chances pour que quelque chose se passe mal quelque part dans un coin obscur du code. Bon nombre de projets dérapent à cause de cela.
Lorsque les systèmes grandissent et que le nombre de tests automatisés est insuffisant, alors la capacité d’un développeur de pouvoir appréhender qu’un changement récent ait provoqué tel ou tel problème s’avère limitée.
Un certain nombre de boîtes informatiques font mal leur boulot en ce qui concerne la prévention des risques techniques, et prennent souvent comme prétexte « de ne pas avoir d’assez bons développeurs » lorsque les problèmes finissent par arriver inévitablement.
Il arrive parfois qu’il y ait davantage de stories faites que prévues car les risques ne se sont pas matérialisés ou que l’apprentissage a été plus facile que prévu.
À d’autres moments, des risques inattendus se produisent et la durée de réalisation des stories explose par rapport à leurs estimations d’origine. Mais la quantité de travail produite chaque semaine demeure inchangée.
Des estimations ont été faites à un moment donné. Elles représentaient la meilleure conjecture qu’ait pu faire quelqu’un sur la quantité d’apprentissage, la quantité de code, et la quantité de risque qu’une story génère. Malgré tout, elles peuvent être en dehors des clous de près de 250 % voire plus.
Les plannings ont tendance à être basés sur les estimations, même si assez souvent cela est fait rétrospectivement afin que les estimations soient basées sur le planning.
L’énoncé du problème « nous avons besoin de 30 points par sprint » amène à penser que le planning d’origine et l’estimation ont été fait sur la base du souhait qu’une chose particulière devait être terminée à un moment particulier, avec la croyance qu’un taux de réalisation élevé pourrait être possible.
Mais, là où le bât blesse, c’est que le vrai travail ne se déroule pas aussi vite qu’on aurait pu l’espérer dans le planning d’origine. Cela laisse le manager dans une situation délicate étant donné que taux réel de réalisation est environ des 2/3 du taux anticipé/espéré de réalisation.
Il y a un vrai risque que 1/3 du projet ne puisse être terminé dans les temps.
Un responsable intelligent comprend bien tout cela, et il va par conséquent priorisé les fonctionnalités les plus importantes à faire d’abord afin de les livrer au plus tôt. De cette manière, lorsque du travail doit sortir du périmètre, ce sont les choses les moins importantes qui sont abandonnées.
Cela signifie non seulement de sacrifier certaines stories mais potentiellement les parties les moins intéressantes de chaque story (cf Story Mapping, la cartographie des stories ; Example Mapping, la cartographie des exemples ; Walking Skeletons, les squelettes ambulants ; Evolutionary Design, la conception évolutionnaire etc).
Une équipe intelligente trouvera – à travers les retours d’informations – quelles parties du projet ne devraient pas être faites. Souvent les gens sur-spécifient et sur-conçoivent. Certaines fois la présence d’une solution simple réduit le besoin d’une solution globale. Cela fait partie intégrante du manifeste agile (sous la dénomination de « simplicité », et définie comme étant « l’art de minimiser la quantité de travail inutile »)
Si nous avons besoin de moins, nous pouvons livrer plus tôt. Si nous pouvons correctement prioriser, nous pouvons sacrifier des choses ayant peu de valeur.
Les retours d’informations des clients améliorent notre priorisation et notre capacité à sortir des éléments du périmètre intelligemment mais cela nous demande de leur livrer du code le plus tôt et le plus souvent possible.
Si les développeurs sont poussés à livrer des solutions brutes, bâclées alors cela augmente le coût des modifications en raison de difficultés plus grandes pour rechercher les modifications et à repérer les problèmes.
Avec tous ces risques qui ont été poussés dans le code, ce dernier peut devenir ingérable. L’équipe peut être amenée à devoir arrêter de produire de nouvelles fonctionnalités afin de le nettoyer. Personne ne veut ça. Il est plus rapide d’écrire du code propre avec de bons tests automatisés plutôt que de finir à passer 80 % du temps des développeurs à nettoyer le bordel et les anomalies.
Ce qui nous amène à nouveau à la dure vérité de cet article :
La durée que cela prend de faire les choses c'est ça la réalité.
Les estimations sont des constructions de toutes pièces.
Blâmer la réalité de ne pas correspondre à la fiction c’est inutile, et blâmer les gens de faire des plannings irréalistes n’est d’aucune aide. Nous sommes là où nous en sommes. Nous devons aller de l’avant.
Cela nous laisse avec un arrière-goût de pessimisme optimiste : si ce travail ne peut pas être réalisé complètement, quelle est la meilleure livraison possible que nous pouvons faire étant donné les ressources, le temps et le périmètre disponible ?
Rendez-vous ici pour la 4ème partie.
Auteur : Tim Ottinger
Source : Q&A on Velocity, Part III
Date de parution originale : 27 juillet 2018
Traducteur : Nicolas Mereaux
Date de traduction : 08/04/2019

Ce(tte) oeuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.